 Home-theater-designers
Home-theater-designers
यदि आप सबसे सरल कार्यों के लिए भी पायथन का उपयोग करते हैं, तो आप शायद इसके तीसरे पक्ष के पुस्तकालयों के महत्व से अवगत हैं। पांडस पुस्तकालय, डेटाफ्रेम के लिए अपने उत्कृष्ट समर्थन के साथ, ऐसा ही एक पुस्तकालय है।
आप कई प्रकार की फ़ाइल को Python DataFrames में आयात कर सकते हैं और विभिन्न डेटा सेट को संग्रहीत करने के लिए विभिन्न संस्करण बना सकते हैं। एक बार जब आप डेटाफ़्रेम का उपयोग करके अपना डेटा आयात कर लेते हैं, तो आप विस्तृत विश्लेषण करने के लिए उन्हें मर्ज कर सकते हैं।
मूल बातें से निपटना
विलय शुरू करने से पहले, आपके पास मर्ज करने के लिए डेटाफ़्रेम होना चाहिए। विकास के उद्देश्यों के लिए, आप प्रयोग करने के लिए कुछ डमी डेटा बना सकते हैं।
कोई आपके सिम कार्ड का क्या कर सकता है
पायथन में डेटाफ्रेम बनाएं
पहले चरण के रूप में, पंडों की लाइब्रेरी को अपनी पायथन फ़ाइल में आयात करें। पांडा एक तृतीय-पक्ष पुस्तकालय है जो पायथन में डेटाफ़्रेम को संभालता है। आप का उपयोग कर सकते हैं आयात पुस्तकालय का उपयोग करने के लिए कथन इस प्रकार है:
import pandas as pdआप अपने कोड संदर्भों को छोटा करने के लिए पुस्तकालय के नाम पर एक उपनाम निर्दिष्ट कर सकते हैं।
आपको शब्दकोश बनाने की आवश्यकता है, जिसे आप डेटाफ़्रेम में परिवर्तित कर सकते हैं। सर्वोत्तम परिणामों के लिए, दो शब्दकोश चर बनाएँ- dict1 तथा dict2- जानकारी के विशिष्ट टुकड़ों को संग्रहीत करने के लिए:
dict1 = {"user_id": ["001", "002", "003", "004", "005"],
"FName": ["John", "Brad", "Ron", "Roald", "Chris"],
"LName": ["Harley", "Cohen", "Dahl", "Harrington", "Kerr-Hislop"]}
dict2 = {"user_id": ["001", "002", "003", "004"], "Age": [15, 28, 34, 24]}याद रखें, आपके डेटाफ़्रेम को बाद में संयोजित करने के लिए प्राथमिक कुंजी के रूप में कार्य करने के लिए, आपको दोनों शब्दकोश मानों में एक सामान्य तत्व की आवश्यकता है।
अपने शब्दकोशों को डेटाफ़्रेम में बदलें
अपने शब्दकोश मानों को डेटाफ़्रेम में बदलने के लिए, आप निम्न विधि का उपयोग कर सकते हैं:
df1 = pd.DataFrame(dict1)
df2 = pd.DataFrame(dict2)कुछ आईडीई आपको डेटाफ़्रेम फ़ंक्शन को संदर्भित करके और दबाकर डेटाफ़्रेम के भीतर मानों की जाँच करने देते हैं चलाएँ/निष्पादित करें . वहां कई हैं पायथन-संगत आईडीई , इसलिए आप उसे चुन सकते हैं और चुन सकते हैं जो आपके लिए सीखना सबसे आसान है।

एक बार जब आप अपने डेटाफ़्रेम की सामग्री से संतुष्ट हो जाते हैं, तो आप विलय के चरण पर आगे बढ़ सकते हैं।
मर्ज फ़ंक्शन के साथ फ़्रेम का संयोजन
मर्ज फ़ंक्शन पहला पायथन फ़ंक्शन है जिसका उपयोग आप दो डेटाफ़्रेम को संयोजित करने के लिए कर सकते हैं। यह फ़ंक्शन निम्न डिफ़ॉल्ट तर्क लेता है:
pd.merge(DataFrame1, DataFrame2, how= type of merge)कहाँ पे:
- पी.डी. पंडों पुस्तकालय के लिए एक उपनाम है।
- मर्ज वह फ़ंक्शन है जो डेटाफ़्रेम को मर्ज करता है।
- डेटाफ़्रेम1 तथा डेटाफ़्रेम2 मर्ज करने के लिए दो डेटाफ़्रेम हैं।
- कैसे मर्ज प्रकार को परिभाषित करता है।
कुछ अतिरिक्त वैकल्पिक तर्क उपलब्ध हैं, जिनका उपयोग आप जटिल डेटा संरचना होने पर कर सकते हैं।
आप मर्ज के प्रकार को परिभाषित करने के लिए कैसे पैरामीटर के लिए अलग-अलग मानों का उपयोग कर सकते हैं। इस प्रकार के मर्ज परिचित होंगे यदि आपने डेटाबेस तालिकाओं में शामिल होने के लिए SQL का उपयोग किया जाता है .
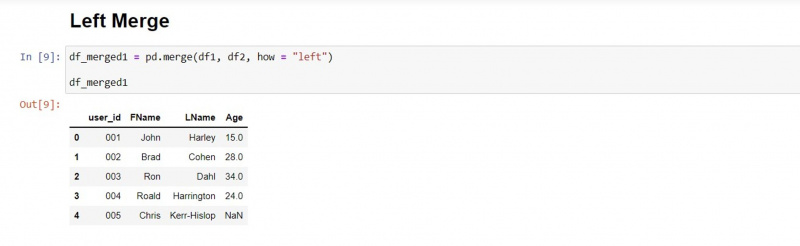
लेफ्ट मर्ज
बायां मर्ज प्रकार पहले डेटाफ़्रेम के मानों को बरकरार रखता है और दूसरे डेटाफ़्रेम से मेल खाने वाले मानों को खींचता है।
फ्लैश ड्राइव को पासवर्ड कैसे प्रोटेक्ट करें
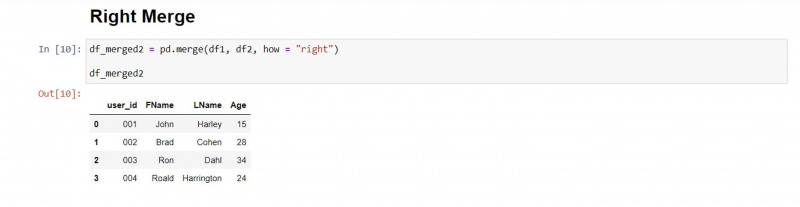
राइट मर्ज
सही मर्ज प्रकार दूसरे डेटाफ़्रेम के मानों को बरकरार रखता है और पहले डेटाफ़्रेम से मेल खाने वाले मानों को खींचता है।
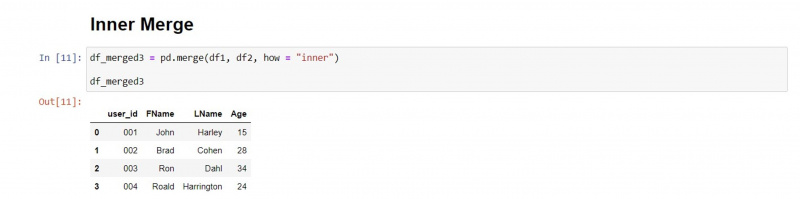
इनर मर्ज
आंतरिक मर्ज प्रकार डेटाफ़्रेम दोनों से मेल खाने वाले मानों को बनाए रखता है और गैर-मिलान मानों को हटा देता है।
बाहरी मर्ज
बाहरी मर्ज प्रकार सभी मिलान और गैर-मिलान मानों को बरकरार रखता है और डेटाफ़्रेम को एक साथ समेकित करता है।

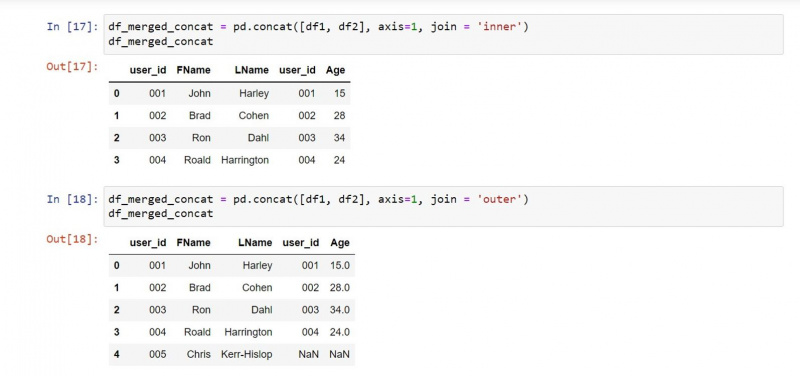
Concat फ़ंक्शन का उपयोग कैसे करें
concat फ़ंक्शन पायथन के कुछ अन्य मर्ज फ़ंक्शंस की तुलना में एक लचीला विकल्प है। कॉनकैट फ़ंक्शन के साथ, आप डेटाफ़्रेम को लंबवत और क्षैतिज रूप से जोड़ सकते हैं।
हालाँकि, इस फ़ंक्शन का उपयोग करने का दोष यह है कि यह डिफ़ॉल्ट रूप से किसी भी गैर-मिलान मान को त्याग देता है। कुछ अन्य संबंधित कार्यों की तरह, इस फ़ंक्शन के कुछ तर्क हैं, जिनमें से केवल कुछ ही एक सफल संयोजन के लिए आवश्यक हैं।
concat(dataframes, axis=0, join='outer'/’inner’)कहाँ पे:
- concat वह फ़ंक्शन है जो DataFrames से जुड़ता है।
- डेटाफ्रेम जोड़ने के लिए DataFrames का एक क्रम है।
- एक्सिस संयोजन की दिशा का प्रतिनिधित्व करता है, 0 क्षैतिज है, 1 लंबवत है।
- जोड़ना बाहरी या आंतरिक जुड़ाव निर्दिष्ट करता है।
उपरोक्त दो डेटाफ़्रेम का उपयोग करके, आप निम्नानुसार कॉन्सैट फ़ंक्शन को आज़मा सकते हैं:
# define the dataframes in a list format
df_merged_concat = pd.concat([df1, df2])
# print the results of the Concat function
print(df_merged_concat)उपरोक्त कोड में अक्ष और जुड़ने के तर्क की अनुपस्थिति दो डेटासेट को जोड़ती है। परिणामी आउटपुट में सभी प्रविष्टियाँ हैं, चाहे मैच की स्थिति कुछ भी हो।
इसी तरह, आप कॉनकैट फ़ंक्शन की दिशा और आउटपुट को नियंत्रित करने के लिए अतिरिक्त तर्कों का उपयोग कर सकते हैं।
सभी मिलान प्रविष्टियों के साथ आउटपुट को नियंत्रित करने के लिए:
73सीएफ12478840एफडीएफएएएबी6993एबीई1316डी356231डीडीसीपरिणाम में केवल दो डेटाफ़्रेम के बीच सभी मिलान मान होते हैं।
कंप्यूटर प्लग इन है लेकिन चार्ज नहीं हो रहा है
पायथन के साथ डेटाफ्रेम मर्ज करना
DataFrames उनके लचीलेपन और कार्यक्षमता को देखते हुए, Python का एक अभिन्न अंग हैं। उनके बहुआयामी उपयोगों को देखते हुए, आप विभिन्न कार्यों को अत्यंत आसानी से करने के लिए उनका व्यापक रूप से उपयोग कर सकते हैं।
यदि आप अभी भी पायथन डेटाफ़्रेम के बारे में सीख रहे हैं, तो कुछ एक्सेल फ़ाइलों को आयात करने का प्रयास करें, फिर उन्हें विभिन्न तरीकों से संयोजित करें।