 Home-theater-designers
Home-theater-designers
एक डेटा विश्लेषक के रूप में, आपको अक्सर कई डेटासेट को संयोजित करने की आवश्यकता का सामना करना पड़ेगा। आपको अपना विश्लेषण पूरा करने और अपने व्यवसाय/हितधारकों के लिए किसी निष्कर्ष पर पहुंचने के लिए ऐसा करने की आवश्यकता होगी।
ps4 नियंत्रक ps4 से कनेक्ट नहीं होगा
विभिन्न तालिकाओं में संग्रहीत होने पर डेटा का प्रतिनिधित्व करना अक्सर चुनौतीपूर्ण होता है। ऐसी परिस्थितियों में, आप जिस प्रोग्रामिंग भाषा पर काम कर रहे हैं, उसके बावजूद जॉइन अपनी योग्यता साबित करते हैं।
दिन का मेकअप वीडियो
पायथन जॉइन SQL जॉइन की तरह होते हैं: वे एक सामान्य इंडेक्स पर अपनी पंक्तियों का मिलान करके डेटा सेट को जोड़ते हैं।
संदर्भ के लिए दो डेटाफ़्रेम बनाएं
इस गाइड में उदाहरणों का पालन करने के लिए, आप दो नमूना डेटाफ़्रेम बना सकते हैं। पहला डेटाफ़्रेम बनाने के लिए निम्न कोड का उपयोग करें, जिसमें एक आईडी, पहला नाम और अंतिम नाम शामिल है।
import pandas as pd
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber"]})
print(a)पहले चरण के लिए, आयात करें पांडा पुस्तकालय। फिर आप एक चर का उपयोग कर सकते हैं, एक , डेटाफ़्रेम कंस्ट्रक्टर से परिणाम संग्रहीत करने के लिए। कंस्ट्रक्टर को एक डिक्शनरी पास करें जिसमें आपके आवश्यक मान हों।
अंत में, डेटाफ़्रेम मान की सामग्री को प्रिंट फ़ंक्शन के साथ प्रदर्शित करें, यह जांचने के लिए कि सब कुछ आपकी अपेक्षा के अनुरूप है।
इसी तरह, आप एक और DataFrame बना सकते हैं, बी , जिसमें एक आईडी और वेतन मान शामिल हैं।
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(b)आप कंसोल या आईडीई में आउटपुट की जांच कर सकते हैं। इसे आपके डेटाफ़्रेम की सामग्री की पुष्टि करनी चाहिए:
पायथन में मर्ज फ़ंक्शन से जॉइन कैसे भिन्न होते हैं?
पांडा पुस्तकालय मुख्य पुस्तकालयों में से एक है जिसका उपयोग आप डेटाफ्रेम में हेरफेर करने के लिए कर सकते हैं। चूंकि डेटाफ़्रेम में कई डेटा सेट होते हैं, इसलिए उनसे जुड़ने के लिए पायथन में विभिन्न कार्य उपलब्ध हैं।
पायथन कई अन्य कार्यों के साथ जुड़ने और विलय करने की पेशकश करता है, जिसका उपयोग आप डेटाफ्रेम को संयोजित करने के लिए कर सकते हैं। इन दोनों कार्यों के बीच एक बहुत बड़ा अंतर है, जिसे आपको उपयोग करने से पहले ध्यान में रखना चाहिए।
ज्वाइन फंक्शन दो डेटाफ्रेम को उनके इंडेक्स वैल्यू के आधार पर जोड़ता है। मर्ज फ़ंक्शन डेटाफ़्रेम को जोड़ता है सूचकांक मूल्यों और स्तंभों के आधार पर।
पायथन में शामिल होने के बारे में आपको क्या जानने की आवश्यकता है?
उपलब्ध जॉइन के प्रकारों पर चर्चा करने से पहले, ध्यान देने योग्य कुछ महत्वपूर्ण बातें यहां दी गई हैं:
- SQL जॉइन सबसे बुनियादी कार्यों में से एक है और काफी हद तक पायथन के जॉइन के समान हैं।
- DataFrames में शामिल होने के लिए, आप इसका उपयोग कर सकते हैं पांडा। डेटाफ्रेम। शामिल हों () तरीका।
- डिफॉल्ट जॉइन लेफ्ट जॉइन करता है, जबकि मर्ज फंक्शन इनर जॉइन करता है।
पायथन जॉइन के लिए डिफ़ॉल्ट सिंटैक्स इस प्रकार है:
DataFrame.join(other, on=None, how='left/right/inner/outer', lsuffix='', rsuffix='',
sort=False)पहले डेटाफ़्रेम पर शामिल होने की विधि को लागू करें और दूसरे डेटाफ़्रेम को इसके पहले पैरामीटर के रूप में पास करें, अन्य . शेष तर्क हैं:
- पर , जो एक से अधिक होने पर शामिल होने के लिए एक इंडेक्स का नाम देता है।
- कैसे , कौन सा जुड़ने के प्रकार को परिभाषित करता है, जिसमें आंतरिक, बाहरी, बाएँ और दाएँ शामिल हैं।
- लसफिक्स , कौन सा आपके कॉलम नाम के बाएं प्रत्यय स्ट्रिंग को परिभाषित करता है।
- rsuffix , कौन सा आपके कॉलम नाम की सही प्रत्यय स्ट्रिंग को परिभाषित करता है।
- क्रम से लगाना , कौन सा एक बूलियन है जो दर्शाता है कि परिणामी डेटाफ़्रेम को सॉर्ट करना है या नहीं।
पायथन में विभिन्न प्रकार के जॉइन का उपयोग करना सीखें
पायथन में कुछ जुड़ने के विकल्प हैं, जिनका आप समय की आवश्यकता के आधार पर व्यायाम कर सकते हैं। यहां शामिल होने के प्रकार हैं:
वयस्कों के लिए घसीट लेखन अभ्यास पत्रक
1. लेफ्ट जॉइन
लेफ्ट जॉइन पहले डेटाफ़्रेम के मानों को बरकरार रखता है जबकि दूसरे से मेल खाने वाले मान लाते हैं। उदाहरण के लिए, यदि आप से मेल खाने वाले मान लाना चाहते हैं बी , आप इसे इस प्रकार परिभाषित कर सकते हैं:
c = a.join(b, how="left", lsuffix = "_left", rsuffix = "_right", sort = True)
print(c)जब क्वेरी निष्पादित होती है, तो आउटपुट में निम्नलिखित कॉलम संदर्भ होते हैं:
- आईडी_बाएं
- फनाम
- नाम:
- आईडी_दाएं
- वेतन
यह जुड़ाव पहले डेटाफ़्रेम से पहले तीन कॉलम और दूसरे डेटाफ़्रेम से अंतिम दो कॉलम खींचता है। यह इस्तेमाल किया है लसफिक्स तथा rsuffix दोनों डेटासेट से आईडी कॉलम का नाम बदलने के लिए मान, यह सुनिश्चित करना कि परिणामी फ़ील्ड नाम अद्वितीय हैं।
आउटपुट इस प्रकार है:

2. राइट जॉइन
पहली तालिका से मेल खाने वाले मानों को लाते समय, सही जुड़ाव दूसरे डेटाफ़्रेम के मूल्यों को बरकरार रखता है। उदाहरण के लिए, यदि आप से मेल खाने वाले मान लाना चाहते हैं एक , आप इसे इस प्रकार परिभाषित कर सकते हैं:
c = b.join(a, how="right", lsuffix = "_right", rsuffix = "_left", sort = True)
print(c)आउटपुट इस प्रकार है:
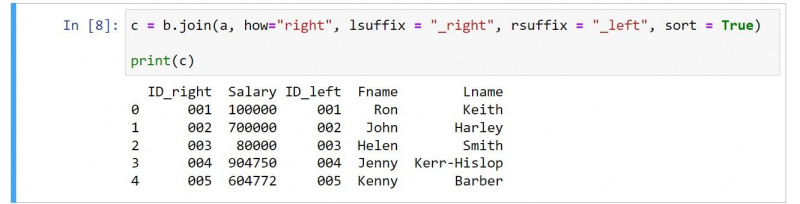
यदि आप कोड की समीक्षा करते हैं, तो कुछ स्पष्ट परिवर्तन होते हैं। उदाहरण के लिए, परिणाम में पहले डेटाफ़्रेम से पहले दूसरे डेटाफ़्रेम के कॉलम शामिल होते हैं।
आपको के मान का उपयोग करना चाहिए सही के लिए कैसे सही जुड़ाव निर्दिष्ट करने के लिए तर्क। साथ ही, नोट करें कि आप कैसे स्विच कर सकते हैं लसफिक्स तथा rsuffix सही जुड़ने की प्रकृति को प्रतिबिंबित करने के लिए मूल्य।
अपने नियमित जॉइन में, हो सकता है कि आप राइट जॉइन की तुलना में खुद को लेफ्ट, इनर और आउटर जॉइन का अधिक बार उपयोग करते हुए पा सकते हैं। हालाँकि, उपयोग पूरी तरह से आपकी डेटा आवश्यकताओं पर निर्भर करता है।
3. इनर जॉइन
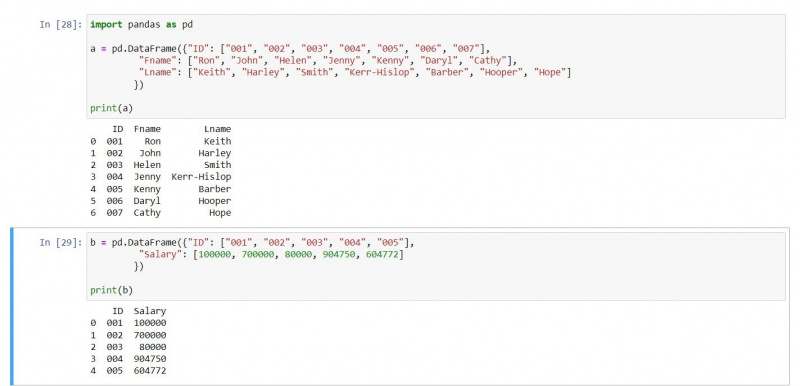
एक आंतरिक जुड़ाव दोनों डेटाफ़्रेम से मेल खाने वाली प्रविष्टियाँ वितरित करता है। चूंकि जॉइन पंक्तियों से मिलान करने के लिए इंडेक्स नंबरों का उपयोग करते हैं, एक आंतरिक जुड़ाव केवल उन पंक्तियों को लौटाता है जो मेल खाती हैं। इस उदाहरण के लिए, आइए निम्नलिखित दो डेटाफ़्रेम का उपयोग करें:
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005", "006", "007"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny", "Daryl", "Cathy"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber", "Hooper", "Hope"]})
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(a)
print(b)आउटपुट इस प्रकार है:
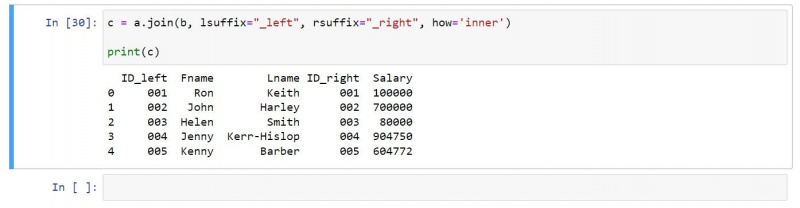
आप निम्नानुसार एक आंतरिक जुड़ाव का उपयोग कर सकते हैं:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='inner')
print(c)परिणामी आउटपुट में केवल पंक्तियाँ होती हैं जो दोनों इनपुट डेटाफ़्रेम में मौजूद होती हैं:
कैसे एक एचडी एंटीना बनाने के लिए
4. बाहरी जुड़ाव
एक बाहरी जुड़ाव दोनों DataFrames से सभी मान लौटाता है। बिना मिलान वाले मान वाली पंक्तियों के लिए, यह अलग-अलग कक्षों पर एक शून्य मान उत्पन्न करता है।
ऊपर के समान डेटाफ़्रेम का उपयोग करते हुए, बाहरी जुड़ने के लिए कोड यहां दिया गया है:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='outer')
print(c)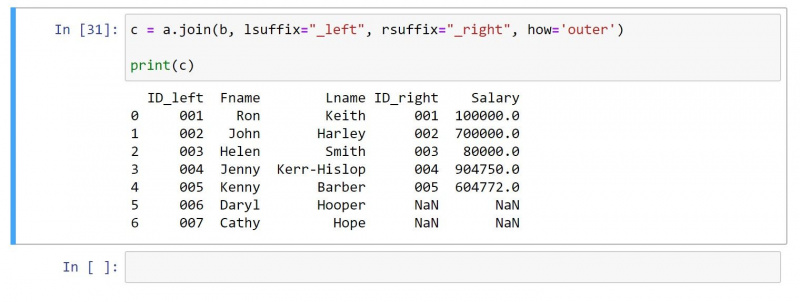
पायथन में जॉइन का उपयोग करना
जॉइन, अपने समकक्ष कार्यों की तरह, मर्ज और कॉनकैट, एक साधारण जॉइन कार्यक्षमता से कहीं अधिक प्रदान करते हैं। इसके विकल्पों और कार्यों की श्रृंखला को देखते हुए, आप उन विकल्पों को चुन सकते हैं जो आपकी आवश्यकताओं को पूरा करते हैं।
आप पाइथॉन द्वारा प्रदान किए जाने वाले लचीले विकल्पों के साथ, परिणामी डेटासेट को जॉइन फ़ंक्शन के साथ या उसके बिना अपेक्षाकृत आसानी से सॉर्ट कर सकते हैं।